Dominik S´ le¸ zak Infobright Inc. 波兰 slezak@infobright.com
Victoria Eastwood Infobright Inc. 加拿大 victoriae@infobright.com
1. 引言
Infobright社区版 (ICE,开源) 与 Infobright 企业版 (IEE,商业许可) 能够对TB数量级的数据执行即席查询[13]。MySQL 可插拔式的存储引擎架构可以帮助用户轻松入门,并提供丰富的数据库功能[19]。基于数据压缩 (参见[11]),列式数据存储 (参见[16]),自适应查询处理 (参见[9]),以及粗糙集理论(参见[22]) 的内部机制为我们的数据仓库应用提供了良好的性能和可伸缩性,既不需要专门的硬件,也不需要高级的调优。
我们方法的关键在于将数据划分为“粗糙行”,每一个粗糙行由64K个原始行组成。我们自动地对粗糙行加上标签,这些标签是与它们数据列值相关的复合信息,通常还包括多列及多表的对应关系。利用这种方式(首先在[27]中被拟定),我们创造出新的信息系统(参见[8]),其对象对应于粗糙行和各种类型粗糙信息的属性。在这种新框架下,数据库操作可以得到有效的支持,并且在粗糙信息不充分时对实际数据的访问也可用。ICE和IEE都基于使用粗糙信息最小化和最优化数据访问的若干算法。
论文的组织结构如下:第2和第3章介绍体系结构和技术的基础知识。第4章展示两个关于粗糙信息结构的例子。第5和第6章描述两个关于核心方法的例子:迭代式的粗糙/精确查询过程和对粗糙信息的无缝式重计算。第7和第8章讨论两个研究项目的例子:关于近似查询的调查和智能数据组织。第9章总结全文。
2. INFOBRIGHT体系结构
Infobright数据仓库软件的ICE与IEE版本都基于同样的体系结构组件。当然,它们在功能上(IEE支持数据的增加/更新/删除操作),以及对操作系统的支持上(ICE同时支持Linux和Windows)有不同之处。IEE商业认购版(在论文中未做讨论)可能在大规模工业应用上更具有优势。另一方面,ICE则提供了一个可供外部开发人员贡献代码的框架。关于ICE与IEE对比的进一步讨论可以参考Infobright论坛。
图1在尽可能高的层次上模拟了我们的体系结构。MySQL管理服务用来做连接池。MyISAM引擎则用来存储诸如表定义、视图和用户权限等目录信息。我们有一套快速批量数据加载的方法。IEE额外地支持更多的MySQL特有的加载机制。我们使用MySQL的查询重写和解析,但是替换了查询优化的主要部分。MySQL优化器作为一个与MySQL存储引擎接口相连的子模块被保留。我们在特殊场合,尤其是在IEE中支持数据的增加/更改/删除操作时使用它。
我们使用“知识网格”这个术语来对第一章中提到过的粗糙信息进行定址。我们对于这个术语的解释不同于其在网格计算或者语义网络[3]中的定义,虽然知识网格作为查询引擎和数据之间的媒介时在某种程度上与它们有一些相似之处。Infobright知识网格中的元素被称为“知识节点”,不要与网格/分布式/并行体系结构[10]相混淆。在本文中,我们只提供了关于知识节点的几个例子。如果想了解关于这个领域的更多细节,可以参照[29]。
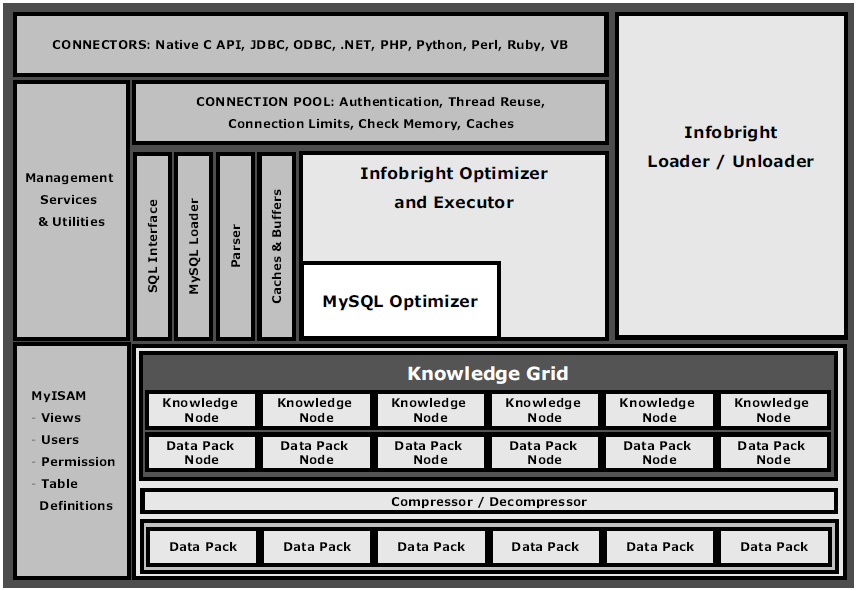
Figure 1 ICE 和 IEE的核心组件与MySQL集成。专用于可插拔存储引擎的标准 MySQL 优化器被整合为更高级的Infobright优化器和执行器的一部分。
图1底部的“数据包”通过对数据执行垂直和横向的分解得到。如第一章中所述,我们将行分组为粗糙行。对于每一个粗糙行,我们分别对每一列进行存储。由此得到的包通过[28]中描述的算法进行分解和管理。现在,数据行只按照粗糙行的形式进行组织。我们在第8章中讨论在未来关于这方面的扩展。
知识网格包含于数据包直接相连的数据包节点。数据包节点提供最基本的统计并能够顺利地对数据包进行访问。它们的用法与一些其他的数据库体系结构[18]部分类似。围绕知识网格额更高级的组件和方法是Infobright所独有的。
3. 基础知识
Infobright优化器可以使用知识网格对查询执行过程中的每一个步骤进行模拟和支持。在[26, 29]中,我们展示了若干使用知识网格内部接口加速执行的查询处理操作。在这里,仅仅是为了说明,让我们来回忆一个最基本的例子,使用知识网格将数据包划分为3种类别:
- 所有数据元素与进一步查询都不相关的不相关数据包
- 所有数据元素均与进一步查询相关的相关数据包
- 基于可用信息无法判定是否相关的可疑数据包
上述3种分类的灵感来源于粗糙集理论[21],其中数据块被拆分为正向的、负向的和边界区域,这与它们的分析概念成员有关。基于粗糙集的算法经常被用于知识发现领域,以寻找有意义的数据依赖(参见[17])。它们也适用于通过采用这种依赖关系来处理查询过滤(参见[15])的方式提升数据库的性能。我们的理念是不同的。我们应用知识网格来计算在精确层次上解析查询所需数据的“粗糙近似”。应当注意的是,我们构建数据块的方法不同于基于粗糙集的原始方法(参见[22])。在另一方面,对于粗糙集基本原则的解释与原始定义保持一致。
4. 知识网格
知识节点应该用优化数据访问的能力来进行评估。关于这一点可以用避免可疑数据包的方式来考虑,或者使用比第5章和第6章中演示的更高级的方式——在单次查询的执行过程中避免将相同的数据包解压多次来考虑。从直觉上看,更加细化的知识节点可能在这方面更加有效。然而,过于庞大的结构将会导致性能的下降。我们接下来列举关于知识节点的两个例子。要了解更多的示例和在查询执行过程中使用知识节点的其它技术,可以参见[26, 29]。我们要强调的是,目前在ICE和IEE中使用的知识节点的规模与实际数据相比几乎微不足道。
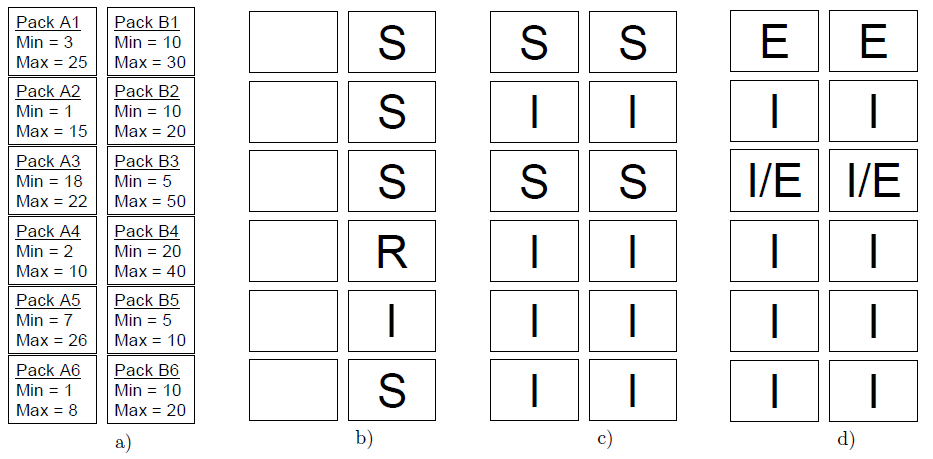
Figure 2: 对第5章的演示: (a)为简化的知识网格; (b,c,d)代表查询执行阶段。R, S 和 I 分别代表相关, 可疑以及不相关的数据包。 E代表在精确层次上的处理。
- 数据包节点包含如下统计信息:最小值和最大值(按照不同的数据类型做具体解释),数值的总和 (数值数据类型),空值的个数以及数据包中元素的总个数。它们在所有的表的所有列中自动创建。第5章阐明了它们如何用于查询分析。值得观察的是除了简单的消除不相关数据包之外,如何利用完全的不相关/可疑/相关数据包分类的优势。
- “包对包”支持一对表之间的等值连接关系。当给定的关系在查询工作载荷中出现时,包对包被自动创建。它是一个与粗糙行对相关的二元关系矩阵。如果我们确定在对应的粗糙行对中没有匹配的行,则矩阵的值为0。如果找到了一对匹配的行,或者引擎干脆还没有机会在精确层检查给定的粗糙行对,矩阵的值为1。可以参考第6章的演示过程。
5. 两级计算
下面的例子最早在[26]中被介绍过。考虑包含350,000行以及列A与B的表T。我们有6个粗糙行:(A1,B1)对应于1-65,536行,(A2,B2)对应于65,537-131,072行,依此类推,(A6,B6)对应于327,681-350,000行。数据节点中可用的最小与最大值如图2a所示。为了使问题简化,假设T中不包含空值,并且忽略其他类型的知识节点。我们关注的查询语句是:
SELECT MAX(A) FROM T WHERE B>15;
根据列B包含的各个数据包的最小值和最大值,B1,B2,B3和 B6是可疑数据包,B4是相关数据包而B5是不相关数据包(图2b)。根据列A包含的数据包的各个数据包的最小值,MAX(A)一定不小于18。因此,只有(A1,B1)和(A3,B3)需要进一步的分析(图2c)。A1的最大值比A3大,因此 (A1,B1)是精确查询层最先被处理的粗糙行。根据其分析结果来决定(A3,B3)是不相关或者还也需要精确层的处理(图2d)。
上面的例子说明“粗糙操作”能够被递归的触发。所有的知识节点共同构建起了一张网,与其下的实际数据相比这张网的规模非常小,但是在更高层次上它却非常的强大。当查询落在这张网上时,知识节点之间相互协作来对查询进行“消费”。如果某个查询非常的“重”,网的一部分就会下沉至精确数据层,但随后它们会被再次拉起。这样一个两级计算策略还可以被应用于数据仓库之外的其它领域。它与诸如粒度计算的范式[23]相类似,其中在颗粒上的计算(在我们的例子中这些颗粒是粗糙行和数据包)与独立的实体(行与单独的数据元素)发生交互。
6. 无缝重计算
大部分目前已经实现的知识节点只要在数据被加载时(或者执行IEE版本的修改操作)就会以联机的方式进行更新。然而,这种对于更高级知识节点的即时性重计算会大幅度降低数据装载的速度。比如说,完成包对包矩阵的创建时,会需要让一张表中某个新增的粗糙行与另外一张表包含的所有数据进行比较。相反,对于代表粗糙行之间关系的知识节点来说,它们与新增(或者被修改)数据相关部分的重计算会被推迟到传入的查询需要访问相关数据时进行。
我们拿包对包关系作为一个案例分析。继续第五章中的例子,执行如下查询:
SELECT MAX(T1.B-T2.B) FROM T AS T1, T AS T2 WHERE T1.A=T2.A AND T1.B>25;
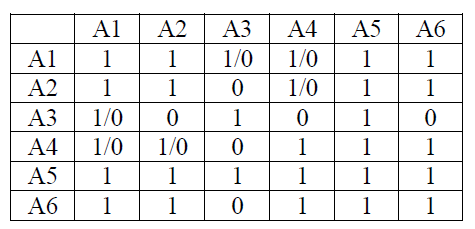
Figure 3: 对第6章的演示说明: 根据列A的数据包节点初始化为0的包对包关系。在查询执行阶段,配对 (A1,A3), (A1,A4) 和 (A3,A4) 的状态可能会从1 变成 0.
假设这是表T关于列A的第一次等值自连接。图3演示了与之对应的包对包关系。在还没有访问数据时,唯一的数据来源如图2a中所呈现的那样。之后,当执行上面的查询时,连接算法访问数据包A1,A3和A4。(其它包属于B>25的不相关粗糙行,因此我们不对它们进行解压)Infobright实现了几种连接技术,每一种都会重新检查诸如(A1,A3), (A1,A4) 和 (A3,A4)的配对。每一个接下来的连接操作都会利用已经经过重计算的包对包关系,如图3中展示的那样,矩阵中的一些1可能会被0代替。这也许会导致较大数量的粗糙行的清除并获得更快的处理速度。向表T中增加新的数据时会发生同样的情景。通过这种方式,知识节点根据用户的需求无缝地进行调整。事实上,包对包关系矩阵中与频繁的查询模式相对应的区域总是会被彻底地刷新。执行多表连接时也是一样的。
7. 近似查询
在[26]中,我们引入了“粗糙查询”这样一个抽象的概念。我们这样做是为了通过知识节点元组(被当做是更高高层次对象的属性)的方式来阐明粗糙行(被当做更高层次的对象)的内部过程。当然,也可以在拓展SQL的上下文中考虑这个问题。它与一个有关近似查询[6, 12]的流行话题相关,这个话题同时也引起了Infobright论坛上一些人的注意。粗糙集的原则在这个领域同样有用。实际上,一些基于粗糙集的近似查询的延伸已经被提出[20]。
尽管近似查询目前不在我们产品的发展蓝图上,我们还是调查了这个领域的一些可能性。比如说,如图4中展示的那样,我们测试了几乎能正确描述数据包的非精确数据节点,忽略一定比例的局部离群点以提供更精确的最小-最大区间。以分析查询答案的速度与精度之比形式得到的结果前景非常有希望。值得注意的是,在一些应用当中,当离群点(参见 [7])被去除时,查询结果实际上更加可靠。在诸如数据压缩(参见[28, 30])或者数据组织(第8章)等方面,针对离群点的处理也可能是有用的。只需要记住图4中的离群点指的是一些异常的值,而第8章中介绍的机制中的离群点则指的是异常的数据行。
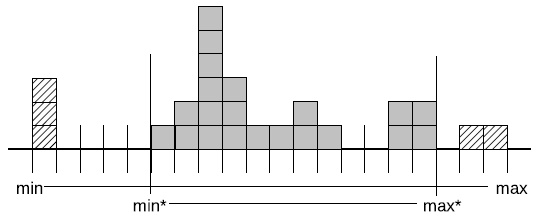
Figure 4: 数据包中的值分布。启发式导出的 min*/max*值被存储在相应的非精确数据包节点中。
8. 数据组织
Infobright的查询性能取决于知识网格的“质量”。质量的定义需要与特定知识节点的角色相适应。比如说,它可能与数据包节点中的最小和最大值的平均接近程度或者包对包关系矩阵中0的个数有关。我们调查了几种使这种质量最大化的粗糙行组合方法,它们既不会导致数据加载速度显著下降,也不需要高级的数据处理。它将我们引向一些与数据挖掘类似的算法原型,尤其是一些增量数据聚类算法[1, 4]。原型设计的细节及其与当前体系结构的集成方法在[25]中进行了描述。
我们技术的一个重要特征是缺乏高级的手工优化。因此,假定这些原型对于用户是透明的。这个观点在图5中得到了说明。每一个行输入都被分配给一个“最近的容器”。容器对刚刚分配的行进行采集。每当某一个容器达到最大限制——64K行时,它包含的内容会作为一个新的粗糙行转发至接下来的处理阶段(知识节点的部分重计算,拆分成数据包,压缩并将数据包存储至磁盘)。与此同时,容器被清空并立即准备好接收接下来的数据。
在我们的原型中,对行容器接近程度的测量基于添加数据行之后容器质量的改变,目前为止质量的历史得分以及在特定容器中当前存储数据行的数量。容器质量应当反映知识节点的质量,并通过其在引擎中使用的频率赋以相应的权重。利用这种方式,我们依靠历史查询的工作载荷,这与一些其它的优化方法一样 [5, 24]。另一方面,整个框架保持联机可用,并且对于工作载荷的变化高度灵活。
图5说明我们也在这个项目中对离群点进行了处理。就这一方面来说,将我们的方法与一些其它的在数据聚类中处理离群点的方法作比较是十分有趣的(参见[2, 14])。在我们的情境下,所谓的离群点是指和当前存储在容器中的内容“相距甚远”的行输入。我们增加了一个特殊的“垃圾”容器来将这些离群点转发给单独的粗糙行。垃圾容器也帮助我们解决了另外一个在装载期间数据模式发生快速改变时遇到的问题。在这种情况下,一些相对比较老的数据行可能会被阻塞在容器中,致使这些容器无法接收新的数据。实际上,这些数据行业被认为是离群点。相应地,我们也把这些阻塞的行扔进垃圾箱中。
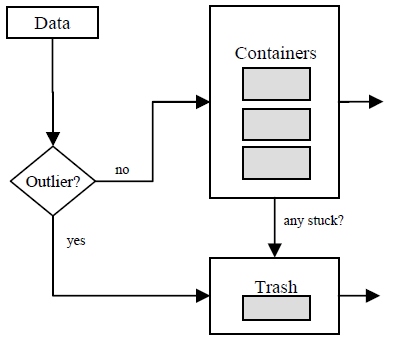
Figure 5: 第8章中讨论的数据组织方法。额外的垃圾容器收集那些和其它容器明显不匹配或者在其它容器中停留时间过长的数据行。
性能测试表明,将图5中展示的方法与当前的Infobright技术相集成,我们可以显著地提高知识节点的平均质量以及查询的整体速度。
9. 结论
论文对Infobright核心技术的几个特定的组件进行了概述。我们也讨论了一些当前的研究项目,在不久的将来,这些项目可能会引起学术界以及工业社区极大的兴趣。
10. 参考文献
[1] C. C. Aggarwal, editor. Data Streams: Models and Algorithms. Springer, 2007.
[2] C. B¨ohm, C. Faloutsos, and C. Plant. Outlier-robust clustering using independent components. In SIGMOD Conference, pages 185–198, 2008.
[3] M. Cannataro and D. Talia. The knowledge grid. Commun. ACM, 46(1):89–93, 2003.
[4] M. Charikar, C. Chekuri, T. Feder, and R. Motwani. Incremental clustering and dynamic information retrieval. SIAM J. Comput., 33(6):1417–1440, 2004.
[5] S. Chaudhuri and V. R. Narasayya. Self-tuning database systems: A decade of progress. In VLDB, pages 3–14, 2007.
[6] S. Chaudhuri, V. R. Narasayya, and R. Ramamurthy. Estimating progress of long running sql queries. In SIGMOD Conference, pages 803–814, 2004.
[7] A. Deligiannakis, Y. Kotidis, V. Vassalos, V. Stoumpos, and A. Delis. Another outlier bites the dust: Computing meaningful aggregates in sensor networks. In ICDE, pages 988–999, 2009.
[8] S. Demri and E. OrÃlowska. Incomplete Information: Structure, Inference, Complexity. Springer, 2002.
[9] A. Deshpande, Z. G. Ives, and V. Raman. Adaptive query processing. Foundations and Trends in Databases, 1(1):1–140, 2007.
[10] J. M. Hellerstein, M. Stonebraker, and J. R. Hamilton. Architecture of a database system. Foundations and Trends in Databases, 1(2):141–259, 2007.
[11] A. L. Holloway, V. Raman, G. Swart, and D. J. DeWitt. How to barter bits for chronons: compression and bandwidth trade offs for database scans. In SIGMOD Conference, pages 389–400, 2007.
[12] Y. Hu, S. Sundara, and J. Srinivasan. Supporting time-constrained sql queries in oracle. In VLDB, pages 1207–1218, 2007.
[13] Infobright. Corporate and community sites. www.infobright.com, www.infobright.org.
[14] A. K. Jain, M. N. Murty, and P. J. Flynn. Data clustering: A review. ACM Comput. Surv., 31(3):264–323, 1999.
[15] N. Kerdprasop and K. Kerdprasop. Semantic knowledge integration to support inductive query optimization. In DaWaK, pages 157–169, 2007.
[16] M. L. Kersten. The database architecture jigsaw puzzle. In ICDE, pages 3–4, 2008.
[17] W. Kl¨osgen and J. M. Z˙ ytkow, editors. Handbook of Data Mining and Knowledge Discovery. Oxford University Press, 2002.
[18] J. K. Metzger, B. M. Zane, and F. D. Hinshaw. Limiting scans of loosely ordered and/or grouped relations using nearly ordered maps, 2005. US Patent 6,973,452.
[19] MySQL. MySQL 6.0 reference manual: Storage engines. dev.mysql.com/doc/refman/6.0/en/storage- engines.html.
[20] S. Naouali and M. Quafafou. Concepts approximation for information retrieval from databases and pragmatic OLAP. In ICTTA, pages 401–402, 2004.
[21] Z. Pawlak. Rough sets: Theoretical aspects of reasoning about data. Kluwer, 1991.
[22] Z. Pawlak and A. Skowron. Rudiments of rough sets. Inf. Sci., 177(1):3–27, 2007.
[23] W. Pedrycz, A. Skowron, and V. Kreinovich, editors. Handbook of Granular Computing. Wiley, 2008.
[24] A. Rasin, S. Zdonik, O. Trajman, and S. Lawande. Automatic vertical-database design, 2008. WO Patent Application, 2008/016877 A2.
[25] D. S´l¸ezak, M. Kowalski, V. Eastwood, and J. Wroblewski. Methods and systems for database organization, 2009. US Patent Application, 2009/0106210 A1.
[26] D. S´l¸ezak, J. Wroblewski, V. Eastwood, and P. Synak. Brighthouse: an analytic data warehouse for ad-hoc queries. PVLDB, 1(2):1337–1345, 2008.
[27] D. S´l¸ezak, J. Wroblewski, V. Eastwood, and P. Synak. Rough sets in data warehousing. In RSCTC, pages 505–507, 2008.
[28] M. Wojnarski, C. Apanowicz, V. Eastwood, D. S´lezak, P. Synak, A. Wojna, and J. Wroblewski. Method and system for data compression in a relational database, 2008. US Patent Application, 2008/0071818 A1.
[29] J. Wroblewski, C. Apanowicz, V. Eastwood, D. S´l¸ezak, P. Synak, A. Wojna, and M. Wojnarski. Method and system for storing, organizing and processing data in a relational database, 2008. US Patent Application, 2008/0071748 A1.
[30] M. Zukowski, S. Heman, N. Nes, and P. Boncz. Super-scalar ram-cpu cache compression. In ICDE, page 59, 2006.
本文链接:http://bookshadow.com/weblog/2014/04/22/infobright-datawarehouse/
请尊重作者的劳动成果,转载请注明出处!书影博客保留对文章的所有权利。
捐赠书影博客
