Evaluation of Recommender Systems -- Recommender systems evaluation strategies, classic evaluation metrics
推荐系统评测—系统评估策略,经典评测方法
The evaluation in the recommender systems domain might be done utilizing several principal approaches, namely, off-line experiment, user studies and online experiments. Selecting the evaluation strategy, it is beneficial to realize the difference among them.
推荐系统可以使用的几种主要的评测方法包括离线实验,用户调研和在线实验。了解这些评测方法之间的区别对于评估策略的选择很有帮助。
Off-line experiments are run on pre-collected datasets of users choosing or rating items. Utilizing such datasets allows to simulate the users’ behavior and to evaluate algorithms efficiency. Significant advantage of this type of experiments that it does not require real users interaction. The downside is that off-line experiments can evaluate a narrow set of aspects, primarily about algorithms prediction or recommendation accuracy. The goal of this approach is to filter out algorithms which have poor performance before the recommender system will be evaluated with a user study or online type evaluations.
离线实验使用预先收集的用户选择或者项目评分数据集。使用这样的数据集可以模拟用户的行为进而评估算法的效率。这种实验的一个显著的优势是它不需要实际用户的交互。该方法的缺点在于离线实验只能评测一个很狭窄的数据集切面,主要是关于算法预测或者评估的准确性。此方法的目的在于对推荐系统执行用户调研或者在线评估之前过滤掉性能较差的算法。
User studies are conducted with a group of people by giving them a set of test tasks and recording observed behavior, collecting quantitative measurements, results of questionnaires, among others. Unlike off-line experiments user studies allow to observe people’s behavior when interacting with the system and collect more various quantitative measurements such as a time spent before submitting a feedback, for example. The principal disadvantage is that they are expensive to conduct in terms of time and costs.
执行用户调研时,为一组用户提供测试任务集并记录观察其行为,收集量化测量数据,问卷调查结果,等等。与离线实验不同,用户调研可以在用户与系统进行交互时观察他们的行为,并且可以收集更多不同的量化测量值,例如提交反馈之前用户花费的时间。该方法主要的缺陷是它需要的时间较多并且成本昂贵。
Online experiments providing the strongest evidence that the recommender system has a value. This type of experiment is usually conducted when off-line and user studies were done, and the system is ready to run in the production state. Online evaluation is unique in terms that they can measure achieved goal, for example, profit increase for the e-commerce recommender system or user retention. While utilizing such experiments one should consider the risk that bad recommendation quality or design might discourage real users preventing them from ever using the system again. Therefore, the system should be evaluated carefully by other strategies before utilizing this strategy. [herlocker2004evaluating]
在线实验可以为推荐系统的评估提供最有力的证据。这种类型的实验通常是在离线实验和用户调研之后完成的,并且系统已经准备好在生产环境中使用。在线评估在测量系统完成目标上的作用是独一无二的,例如,电子商务推荐系统的收益提升或者用户停留时间。然而,使用这种实验方法时应该考虑到这样的风险:较差的推荐质量或者设计可能会打消实际用户再次使用系统的积极性。因此,系统在使用此策略之前应该使用其它策略仔细评估。
Recommender systems might be evaluated against various aspects of a recommender system, namely, functional and non-functional.
推荐系统的评估可以考虑各种不同的方面,亦即,功能性的和非功能性的。
Functional aspects are typically the performance accuracy of utilized algorithms. It includes such accuracy metrics as predictive accuracy metrics measuring how accurate the recommender system predicts ratings or recommends top-N lists of items.
功能性方面通常是推荐系统所用算法的性能精度。其准确性测量包括对推荐系统预测评分或者top-N项目推荐列表的准确性度量。
To measure accuracy in off-line experiments, a relevant dataset must be selected. Usually, the dataset is randomly divided into two parts: 80% as a training set and 20% as a test set of ratings. The algorithm “learns” from the train set and makes assumptions about ratings in the test set.
要测量离线实验的准确性,必须选择一个相关数据集,数据集随机分为两部分:80%作为训练集,20%作为评分测试集。算法从训练集中“学习”然后对测试集的评分进行预测。
The difference between predicted and actual ratings forms a basis for an accuracy metrics. Remarkable and one of the widely used accuracy metrics is Mean Absolute Error (MAE).[Herlocker 2004, Shani 2011] It measures overall error differences between a predicted rating and the real rating to a total number of ratings in the test set.
预测评分和实际评分的差异形成了准确性测量的依据。最著名和使用最为广泛的测量指标就是平均绝对误差(MAE)。它测量了测试数据集全部预测评分和实际评分之间的误差。
As the name suggests, the mean absolute error is an average of the absolute errors 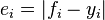 , where f_i is the prediction and y_i the true value. Note that alternative formulations may include relative frequencies as weight factors.
, where f_i is the prediction and y_i the true value. Note that alternative formulations may include relative frequencies as weight factors.
顾名思义,平均绝对误差是绝对误差的平均值,其中fi是预测值而yi是实际值。有时候公式可能会将相关频率作为权重因子。
Another functional metrics is coverage. It measures the percentage of items for which the recommender system can produce recommendations. Catalog coverage measures the percentage of items for which the recommender system has ever made recommendations from the total available number of items. There might be items for which the system can potentially make a recommendation, but the algorithm never suggests those items.
另一个功能性评价指标是覆盖率。它测量了推荐系统产生推荐项目的占比。目录覆盖率测量的是推荐系统做出的推荐项目占全部可用项目个数的比值。可能会存在推荐系统潜在可以推荐的项目,但是算法不包括这些项目。
The learning rate also belongs to non-accuracy functional metrics and measures how quickly the RS achieves a reasonable recommendation level for recently introduced items or users. Also it might measure what is the cutoff in the number of ratings the system needs to be able to make reasonable recommendations and not almost random ones. Reasonable in the context means the level when the system has already collected enough ratings, so that its further increase does not significantly improve the accuracy. The most common method to evaluate the learning rate is to plot a prediction quality versus number of items.
学习速率也属于一种非准确性功能性测量指标,能够评测推荐系统达到为新增项目或用户做推荐的合理水平所需的时间。它也可以度量系统做出合理推荐(不再是随机推荐)所需的评分个数的下限。前文提到的“合理”是指系统已经收集到了足够多的评分,以至于其后续的增加不再显著提升评分的准确性。最常用的评估学习速率方法是绘制预测质量-项目个数的散点图。
Non-functional aspects are usability, scalability, robustness, users’ trust, among others. These aspects do not affect the quality of recommendations, but have direct influence on users’ satisfaction when they use the system.
非功能性方面包括可用性、可扩展性、健壮性、用户信任程度等内容。这些方面不影响推荐的质量,但是会直接影响用户对于他们使用系统的满意程度。
To summarize, the prediction accuracy does not always guarantee users’ satisfaction. Other aspects should also be considered to success with the design of the RS. Choice of the experimental approach defines available evaluation metrics; therefore, this is beneficial to conduct a set of different experiments whenever this is possible. In the following section, the challenges RS are facing are described. Resolving existing limitations leads to an increase in users’ satisfaction.
总结全文,预测准确性并不总能够确保用户的满意程度。要设计一个成功的推荐系统也应当考虑到其他方面的因素。实验方法的选择定义了可用的评估度量;因此,在条件允许时进行一组不同的实验是有益的。
原文链接:http://recommender.no/info/evaluation-of-recommender-systems/
本文链接:http://bookshadow.com/weblog/2014/06/07/evaluation-of-recommender-systems/
请尊重作者的劳动成果,转载请注明出处!书影博客保留对文章的所有权利。
捐赠书影博客
